
Data integration solutions are crucial to managing the enormous volumes of data produced today.
For the modern enterprise, effective data management is key to success. An organization’s ability to use all available business intelligence effectively and efficiently determines how well it can deliver for its customers.
One major challenge businesses face is how to bring disparate data sources together to the best effect. That’s where data integration comes in. .
In this article, we’ll explore what it is and the various data integration tools and processes commonly used. We’ll also look at some of the challenges (and solutions) you’ll encounter on your journey.
Defining data integration and what it means for your business
In 2023, businesses gather and generate data from numerous sources, which can eventually become a problem. If enterprise data accumulates in silos, it can cause inefficiencies that negatively impact workflows.
Data integration processes and solutions like iPaaS can solve this problem by enabling the business to access various data sources from one unified platform.
This means your business can take full advantage of data-driven efficiencies, thus creating more opportunities to optimize your day-to-day operations.
The common types of data integration technologies today
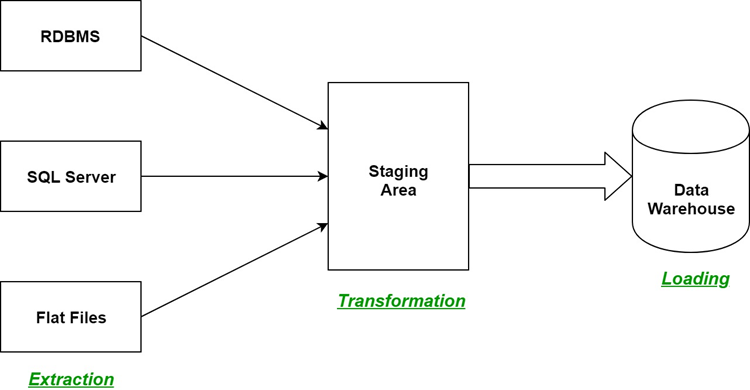
ETL
Extract, transform, load (ETL) is one of the most widely known data integration processes. It involves extracting data from a source system, transforming it in some way, and then loading it to another location, such as a data lake or data warehouse.
ETL became a popular option when traditional on-premises storage was the norm. The ability to transform data—for example, by removing unwanted data—reduced the costs of storing it on-site. However, this process has a major downside.
Because the transformation happens before the data is loaded, you have to know what it will be used for before starting the process. This is so it can be stored in the correct format.
Since cloud environments have become more popular for business operations, the alternative ELT (extract, load, transform) process, which stores data in such a way that it remains accessible in its raw format, has become more widely used.
EII
Enterprise information integration (EII) delivers integrated data sets on demand. It involves the creation of a virtual layer through which underlying data sources can be viewed.
One big advantage of EII is that it can integrate real-time data changes, which makes it handy for numerous business use cases. Essentially, it allows users to access data from a range of sources as if it were part of a single database.
EDR
Finally, we have enterprise data replication (EDR), a data consolidation approach that moves data from one place to another. In its most basic form, this can mean taking data sets from one database and putting them in another that has the same schema, almost like a “drag and drop”.
Finally, we have enterprise data replication (EDR), a data consolidation approach that moves data from one place to another. In its most basic form, this can mean taking data sets from one database and putting them in another with the same schema, almost like a “drag and drop”.
However, there are also more sophisticated EDR data integration tools that enable the movement of data between the source and target databases of different types. The data is replicated in real-time, sporadically, or at specified intervals as required.
Examples of data integration processes you might want to consider
Integration by manual techniques
This is where many businesses start. Without automated data integration solutions, the only way to make sense of data spread across multiple sources is for analysts to log in and work it out themselves.
This means human beings find, output, and analyze data, then write reports that quickly become outdated since the content doesn’t update automatically to reflect real-time changes. In the world of big data and the IoT, this isn’t ideal.
Integration by virtualization
Virtualization involves presenting users with data from different sources together in one viewable layer. The data itself never actually moves; it just looks as if it has, in much the same way that you get a unified view of your work colleagues while video conferencing, even though you’re all in different rooms.
One downside of data virtualization is that it can complicate running analytics queries since the virtualization layer can act as a bottleneck.
Integration by multiple applications
An alternative is direct application integration, where you link multiple applications together. This linking can be done using a variety of methods, including application integration tools, point-to-point communications, or a middleware layer like an enterprise service bus (ESB).
The duplication that results from data replication using this framework can be a drawback. That’s not only because it can lead to a significant increase in point-to-point traffic but also higher running costs overall.
Integration via data warehouse or data lake
Data warehouses and data lakes are two well-established types of data architecture. The benefit they offer as data integration platforms is that they’re centralized repositories offering users unified access to all the data they need.
For example, you can use this approach to accumulate all your Google Analytics data with your Salesforce data to create a unified view of your customers, enabling you to automate the generation of key insights.
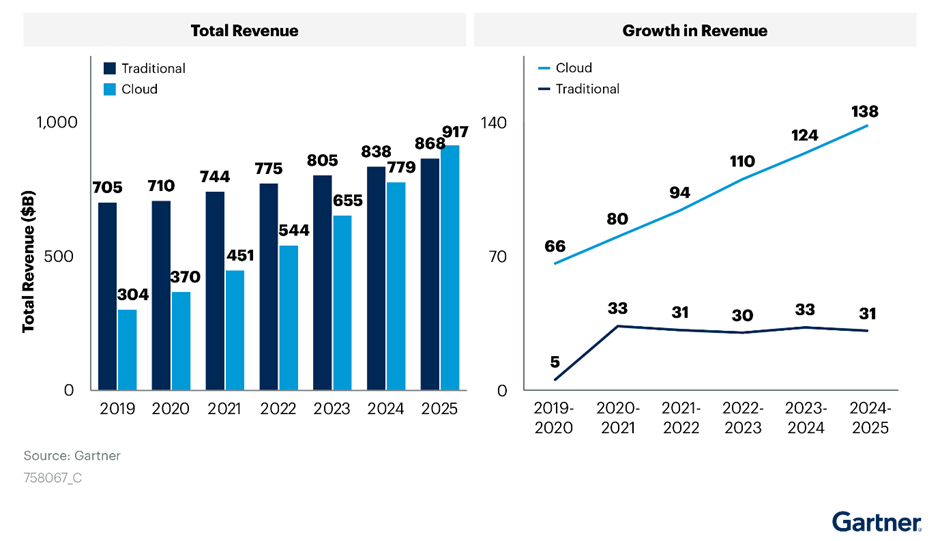
Over the past decade, there has been a shift toward using cloud-based data lake services from providers like AWS. This has led to the development of a whole host of high-performance cloud integration solutions.
According to Gartner, this is part of a wider trend of data migration to the cloud, and global enterprise spending on cloud solutions is expected to overtake spending on traditional IT by 2025.
Integration by data consolidation
Integration via data warehouses or data lakes is a specific example of data consolidation, but this also refers more generally to the concept of integrating data from different sources by bringing it together in a centralized location.
What makes data consolidation different from other data integration processes is the data latency problem. When you access data via a central source, it may not have been updated with the most recent changes.
Depending on the data integration tools and frameworks used, the time that elapses between the data being updated in real-time and those changes being reflected in the centralized repository can be anything from fractions of a second to several hours.
Integration by data federation
Data federation involves serving up data on demand to users and front-end apps. It uses a virtual database featuring a unified data model to integrate distributed data.
Much like data virtualization, the data doesn’t actually move. The difference between these two data integration processes is that data federation converts different data into a common model while providing a single data source for users.
Integration by data propagation
Another technique for integrating data is data propagation, where the data is distributed from a storage location like a data warehouse to local access databases. This is commonly executed using application integration or data replication.
Integration by data mesh
Recently, an innovative approach to data management and integration has also emerged: the data mesh. The idea is to improve users’ data access by directly connecting enterprise data owners, producers, and consumers.
In practice, this means changing how we think about data. Within the data mesh context, it’s treated more as a product in itself than a resource.
The goal of data mesh-driven integration is to enable users to have all the necessary data directly at their fingertips, cutting out the IT middleman.
Challenges you’ll face when you decide to undergo data integration
Data from legacy or new systems
When you first start to investigate the realities of integrating volumes of data from old legacy systems, the challenge can seem insurmountable, particularly for organizations that have been around for a long time. Many are still running on data architectures going back 20 or 30 years—or longer.
For example, if you’re still running operations on an IBM mainframe, you may be using legacy software that won’t run on newer modern platforms. If that software manages critical business functions, how do you upgrade without suffering costly downtime?
You also need to think about future-proofing your data integration solutions as much as possible. The data integration processes you choose need to be able to cope with the demands of new systems later.
Integrating external data
While there are many efficiencies to be gained from integrating structured and unstructured data internal to your organization, integrating data from external sources unlocks even more potential.
For example, data integration solutions for healthcare systems often focus on data sharing between organizations to improve the patient experience.
Unfortunately, achieving smooth data services integration isn’t always easy. Third-party data sets will often come from several sources in multiple formats, and their quality will vary.
Data doesn’t stay static either; it changes constantly and in real time. Shaping your data integration strategy to handle such complexity is difficult.
Integrating with the wrong service or tool
This can happen when the engineers designing integration processes don’t have a clear understanding of the end-user capabilities or use cases at the other end of the data pipeline.
If staff in your organization find the new data services too time-consuming or difficult to operate, that’s not a data integration solution—that’s a problem.
Modern solutions like a hybrid integration platform make this issue less likely to occur. Nevertheless, spending time profiling your organization’s needs is vital before developing a new master data management and integration plan.
What should you really be looking for in a data integration solution or application
Cloud-friendly
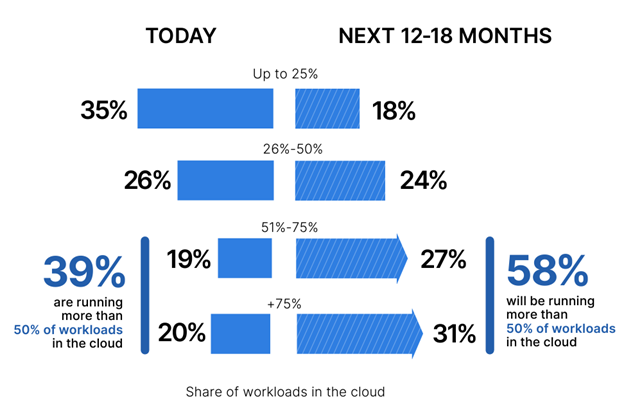
It’s impossible to contemplate a future without cloud apps. According to a 2022 survey of cybersecurity professionals by Fortinet, 39% of respondents’ organizations operate with more than half of their workloads in the cloud, while 58% plan to be doing so in the next 12-18 months.
Intuitive UI
We live in a self-service culture. We’re used to interacting with web services and apps that are a cinch to get used to. Most people have no patience for a sharp learning curve, particularly for how to use tools they didn’t choose themselves but are obliged to get to grips with for work.
So, to keep staff morale high and minimize the potential for human errors resulting in delays or security issues, ensure the user interface is as intuitive as possible.
Ready for hybrid integrations
The data integration solution you choose needs to be flexible and able to adapt to a variety of business needs. Connecting applications, data, and third-party partners is easiest with a platform that can operate across both cloud and on-premises systems.
A solution that’s primed for hybrid integrations will make those capabilities available to you from the start. An API integration platform is a good choice since it works well with existing systems and offers flexibility.
Seamless data movement
In data integration, seamless movement refers to successfully integrating new hardware or software without causing any errors or complications in the existing system.
This is obviously an important goal in any kind of enterprise environment, where business interruption due to data management failures can lead to organizations losing tens of thousands of dollars a day (or more). Evidently, this is a critical factor when you’re selecting an appropriate data integration platform.
Powerful security features
The downside of the big data era is that the risk of security breaches has grown. Traditional kinds of data integration with relational databases can create vulnerabilities, and business leaders must ensure that upgrading systems won’t jeopardize their operations. So, choosing data integration tools and apps with robust security features is a must.
Data architecture can prioritize data privacy
Safeguarding data privacy isn’t only a legal obligation; it’s key to maintaining client trust. According to the Pew Research Center, 81% of Americans think the potential risks of data collection by companies outweigh the benefits. Reassuring your customers about their data privacy is, therefore, crucial.
With the right data architecture, businesses can ensure they keep sensitive information, such as customer details, safe. Data integration apps that include appropriate business context management tools and deletion capability protocols are a sound choice.
Unify your data trapped in legacy systems with the best integration solution—OpenLegacy
The OpenLegacy Hub offers the best legacy and core on-prem systems integration solution on the market today. With its core-to-cloud approach, it enables your business to deploy new digital services from legacy systems within a matter of days.
Whatever your legacy system, be it mainframe, IBM i (AS/400), VSAM, DB2, Oracle, JD Edwards, or SAP-based, OpenLegacy can integrate with your on-premises apps quickly and efficiently to deliver the best results in any cloud or hybrid environment—with no complex middleware to slow down the process.
There’s no need to change your core systems, and implementation doesn’t require any special skills. Your services can be managed as cloud-native applications, allowing for straightforward workflows.
Data security is assured since customer data is never stored in an OpenLegacy Hub repository. Instead, the platform uses APIs and microservices created around the legacy system to manage data and perform real-time transactions.
OpenLegacy also partners with the best iPaaS players on the market, as well as leading data management and data governance tools, to allow OpenLegacy’s unique ability to integrate with the most complex legacy, core, and on-prem systems out there.
FAQs about data integration solutions
How do you implement data integration?
Implementing enterprise data integration solutions begins with assessing your current and future business needs. This enables you to set clear goals for your data integration project.
The next stage is to ensure you understand the systems you already have in place. If one system is running on Microsoft SQL servers and another on Oracle databases, ensure they’re configured appropriately.
Assess your current capabilities so you’re well prepared. Is there sufficient connectivity between your systems? Will your legacy systems continue to contribute data when the project is completed?
Then consider the data itself. It’s important to have a good grasp of what kind of data it is (structured or unstructured), the quality, which data sources are vital, and so on. It’s also crucial to think about how it’s going to be processed since this will have an impact on how the new system is designed.
The careful selection of the right data integration platform for your business is key. Modern data integration tools, like OpenLegacy, use APIs and microservices to enable digital services to be deployed quickly on top of existing legacy systems.
What is a data integration API?
An API is an application programming interface. Essentially, it’s a software tool that enables two or more programs to communicate with one another. You can think of it as a kind of messenger, allowing apps to share information.
In data integration, APIs are used to collect data and deliver it to target applications in the required format. This means that it doesn’t matter what kind of data you have or where it needs to go; it’s possible to create APIs that can integrate the data according to how it needs to be deployed.
What are the steps in data integration?
While there are multiple possible approaches to data integration, the basic concept is the same. The first step is data ingestion, which means bringing data into the system from different sources. This can be done either in batches at specific intervals or in real-time.
The second step involves moving the data to a chosen destination for storage or analysis as required. In some data integration processes, such as ETL, there’s an intermediate data transformation step where data is cleaned up, simplified, or otherwise changed in some way before being moved to its target destination.
We’d love to give you a demo.
Please leave us your details and we'll be in touch shortly